一个numa远程内存访问导致的性能问题
一个numa远程内存访问导致的性能问题
问题
笔者基于C++ grpc异步API封装了一个框架。框架介绍如下:
- 提供一个辅助类型,业务程序通常使用它。
- 它有一个工作线程函数,用于处理grpc event。
- 此辅助类型含有一个map成员,它的工作线程会使用此map成员。
笔者再基于此框架编写了一个简单的性能服务程序,现在测试它的性能。分为两种场景测试:
- 1个辅助类型对象,每个对象使用一个工作线程。即总共只有一个工作线程。
- 6个辅助类型对象,每个对象使用一个工作线程。即总共有六个工作线程。
测试结果:
- 1个辅助对象时QPS为5万。CPU为100%。
- 6个辅助对象时QPS为15万。CPU为600%。
当然,以上CPU利用率抛开了出此辅助类型工作线程之外的其他线程的利用率。
测试结果的问题在于:当使用了6倍CPU时,整体QPS并没有x6,也就是说,单个线程完成的QPS却下降了。
分析
通过perf分析。
1个辅助对象时,如下图所示:
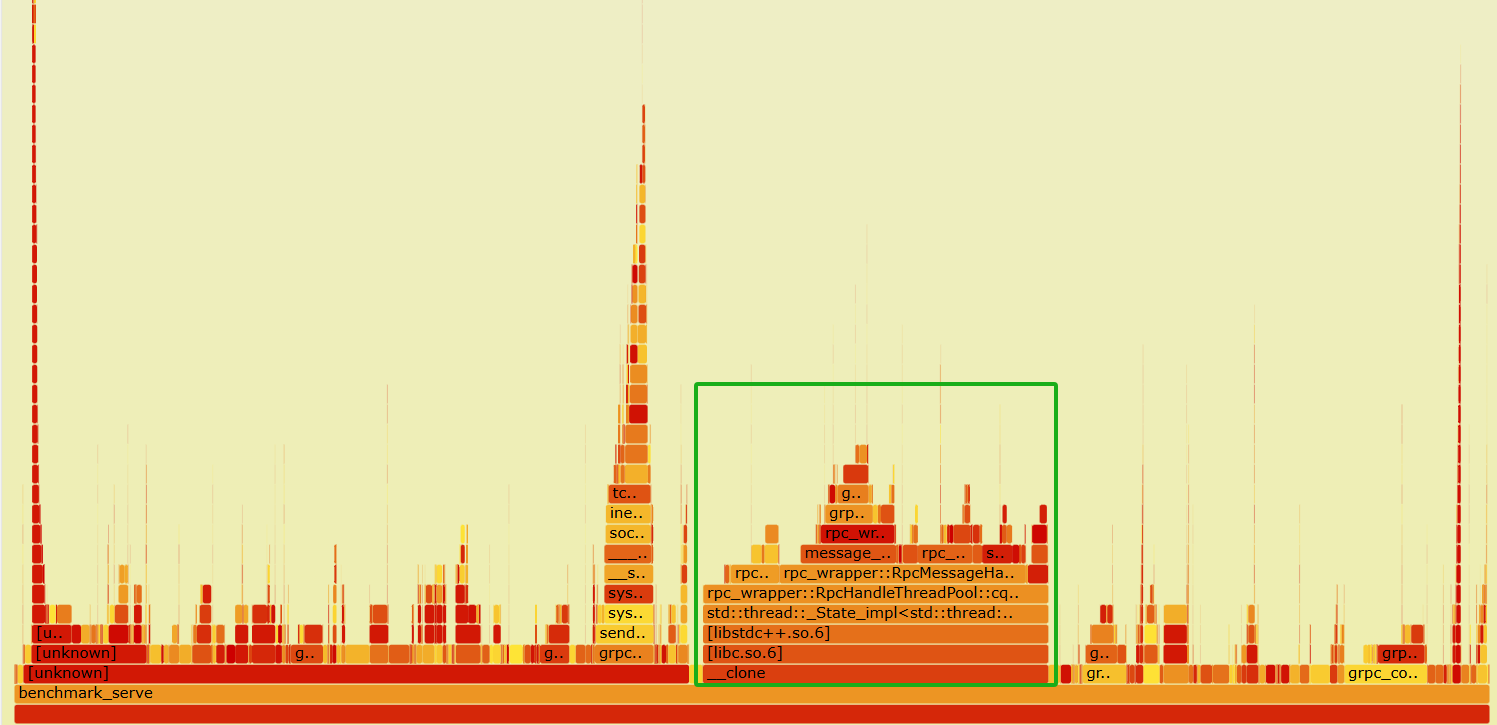
6个辅助对象时,如下图所示: 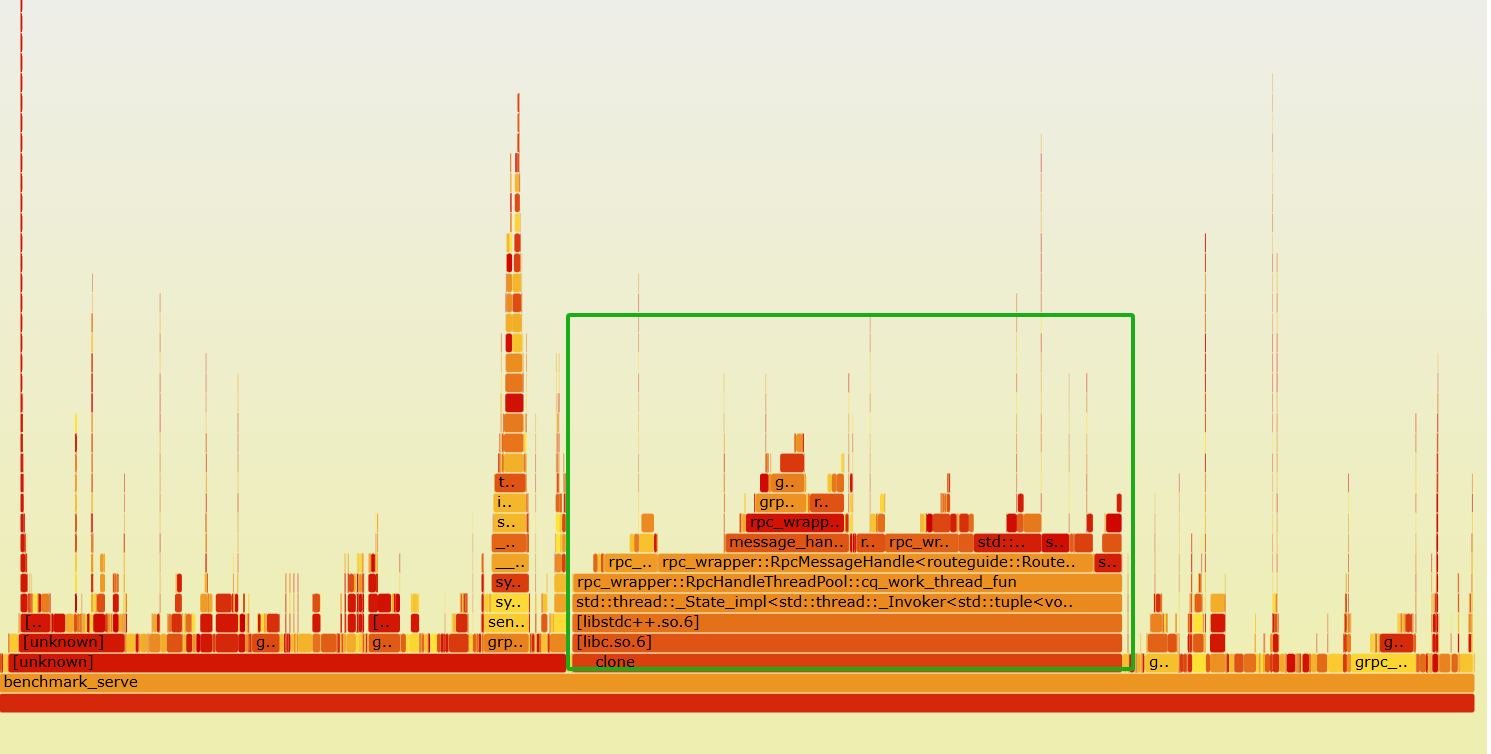
发现6个线程比1个线程的情况下,map和锁的占比变大了(大概占了单核的1/5)。
但火焰图仅仅是一个静态的图像结果,无法知道其原因。
是否工作线程里获取事件的次数变多了呢?这也可能导致函数调用次数变多而增加了CPU占比,但通过验证,并非如此。
但map性能不应该这么低,编写简单的程序表明:map的操作每秒可以执行几百万次,即便多个线程下–每个线程处理自己的map,也能达到几百万次(虽然略有下降)。 而,性能测试服务中,QPS仅为几万,此时map操作也就十万级别,不应该占用那么多CPU。
然后通过perf分析cache miss、伪共享,都没有得出可疑的原因。
朋友隐约提出过numa调度相关的问题,但没有直接怀疑是它导致的。
当没有其他方式之后,我决定使用vtune试试。
当使用vtune分析memory access后,发现:
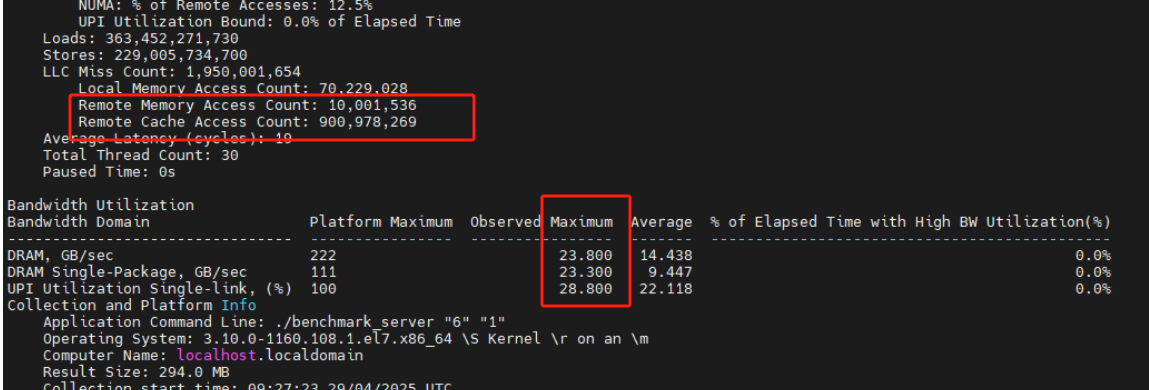
可以看出远程内存访问非常多,朋友建议使用numactl绑核试试。
于是通过:numactl --cpunodebind=0 --membind=0 ./my_app运行,果然性能得到了提升。
总结
- perf火焰图只是静态结果,无法表明根本原因:比如函数调用次数多导致的?比如memory access?比如cache miss?
- 内存访问导致的CPU开销非常可观!
TODO
- 如果只设置
numactl --localalloc并不能解决问题,那么是什么导致的远程内存访问呢?是线程发生了迁移?毕竟,代码里分配的内存 – 注册到grpc,最终都还是由注册它的所在线程在处理,也即:代码并不会在A线程分配一个对象,然后在B线程使用此对象。 回答:是的,发生了迁移。 使用perfetto分析得到,线程跨numa迁移了。
This post is licensed under CC BY 4.0 by the author.